.avif)
Score Vendors on AI-Generated Code Security Expertise First, Not Generic Dev Skills
Veracode research found that 45% of examined AI-generated code contains security vulnerabilities. Cloud Security Alliance data shows AI-assisted commits expose secrets at 3.2% versus 1.5% for human-only commits, more than twice the rate of credential leakage. When you choose a vibe coding rescue vendor, you are choosing who will absorb that liability. Evaluate them on AI security expertise, architecture audit methodology, and a verifiable production hardening track record, not on hourly rate or generic developer headcount.
The failure modes in vibe-coded MVPs are categorically different from the bugs in human-written legacy code. A rescue vendor must demonstrate specific competence in finding and remediating AI-generated code security vulnerabilities, or they will miss the classes of issues that will actually sink your product.
A December 2025 CodeRabbit analysis of 470 open-source GitHub pull requests found AI-co-authored code carried 2.74x higher security vulnerabilities and 75% more misconfigurations than human-only code. These are not random bugs distributed evenly across a codebase. They cluster in predictable places: API routes the model generated without authentication checks, input fields where prompt injection is possible, and third-party packages the model hallucinated into existence. That last category has a name: slopsquatting. A developer who has never worked with LLM-generated code in production may not recognize the term, let alone know where to look for it.
A reasonable objection: any competent senior developer can run SAST tools and fix vulnerabilities. The tools are standard. Semgrep, Snyk, Bandit, OWASP ZAP: none require AI-specific expertise to install and run. But passing a SAST scan on vibe-coded code is not the same as securing it. Traditional SAST misses prompt injection surfaces entirely. It does not flag a hallucinated package dependency sitting in your requirements file. It does not catch a missing authorization check on an AI-generated REST endpoint that looked syntactically correct but was never tested against an authenticated user boundary. Vendors without LLM production experience routinely miss these classes, because they are scanning for what SAST looks for, not for what vibe coding produces.
On rescue engagements we have run, the first deliverable is a SAST/DAST scan combined with a manual review against the Cloud Security Alliance Secure Vibe Coding Guide checklist: hardcoded secrets, prompt injection surfaces, missing input validation, and broken auth. We treat SOC 2 compliance posture as a precondition. If the rescued system will handle customer data, the rescue plan must close the gap to SOC 2 controls before any feature work resumes. That sequencing matters. Vendors who start patching features before closing security gaps are optimizing for visible progress at the expense of the structural problems that created the rescue engagement.
Ask every vendor on your shortlist to name the specific vulnerability classes they look for in AI-generated code. If they cannot name slopsquatting, prompt injection surfaces, and broken auth on AI-generated routes without hesitation, their general development competence will not protect you from the security risks of vibe coding you are already carrying.
Demand a Written Architecture Audit Methodology Before You Sign Anything
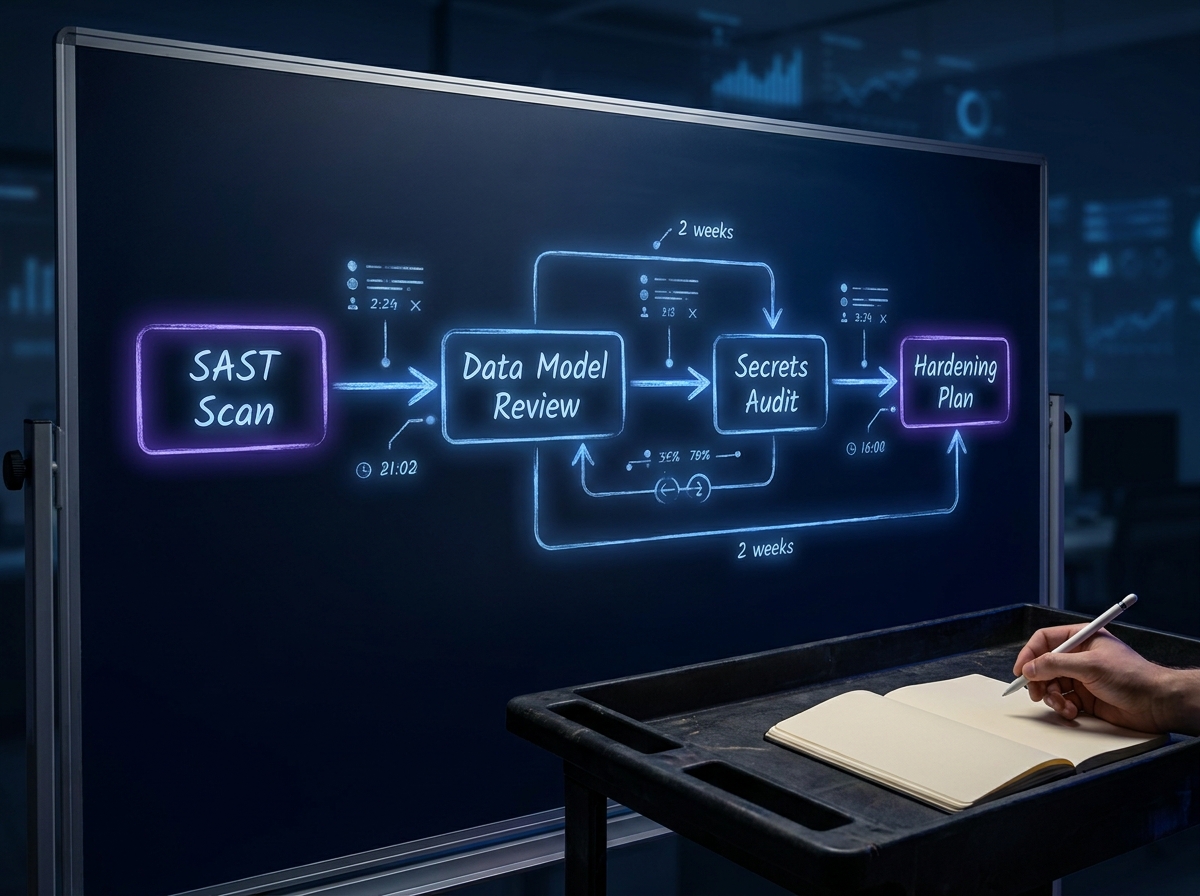
Security competence tells you a vendor can identify what is broken. The next question is whether they can systematically diagnose the codebase they are inheriting.
A credible rescue vendor produces a documented architecture audit and technical debt assessment in the first two weeks of engagement. If they cannot show you sample audit reports from prior work, they are improvising and you are paying for the learning curve.
Rescue work is emergency surgery on the architecture itself. Refactoring core backend services, introducing missing layers for auth, logging, observability, and configuration management, and often completely rebuilding the backend while preserving the frontend: none of this can be done responsibly without a deliberate audit framework. Ad-hoc fixes on a vibe-coded system do not reduce risk. They redistribute it into parts of the codebase you have not examined yet.
Vibe-coded systems accumulate three distinct classes of technical debt, and a real audit methodology names and scores all three. Maintainability debt shows up as inconsistent style, missing documentation, and no tests. Security debt shows up as the 2x secret exposure rate documented by Cloud Security Alliance research. SDLC and process debt shows up as no peer review, no threat modeling, and unclear ownership of critical paths. Vendors who produce a single "findings" document without separating these categories are giving you a bug list, not an architecture assessment.
The Sparks & Honey Q™ platform rebuild is a useful reference point. The engagement started with a phased architecture audit that separated what to preserve, including the UX and customer-facing flows, from what to rebuild, including the backend, data layer, and GenAI integration. That sequencing produced a fully decoupled architecture with 24/7 availability. The audit was not a delay before the real work. The audit defined what the real work was.
Some CTOs will object that a two-week audit is just billable hours before real work starts: they need builders, not auditors. The reframe: the audit is a fixed-scope, fixed-fee deliverable with a tangible artifact at the end, the report and the remediation plan. It gives you a document you can take to your board. It converts an open-ended rescue engagement into a scoped program with a defined phase gate. Vendors who skip the audit and start coding are the ones who generate scope blowouts six weeks in, because they are discovering the architecture's structural problems in real time, on your budget.
Require the vendor to show you a sample audit deliverable before you sign. Not a slide deck. Not a sales narrative. The actual report template, with debt classification, prioritized findings, and a remediation roadmap. If they do not have one, they have not done this work systematically before. The AI readiness assessment framework defines the minimum diagnostic scope a vendor should cover before any remediation work begins. A vendor who walks in ready to build without first mapping what they are building on is deferring costs you will pay later.
Verify Production Hardening Track Record and Watch for Specific Red Flags
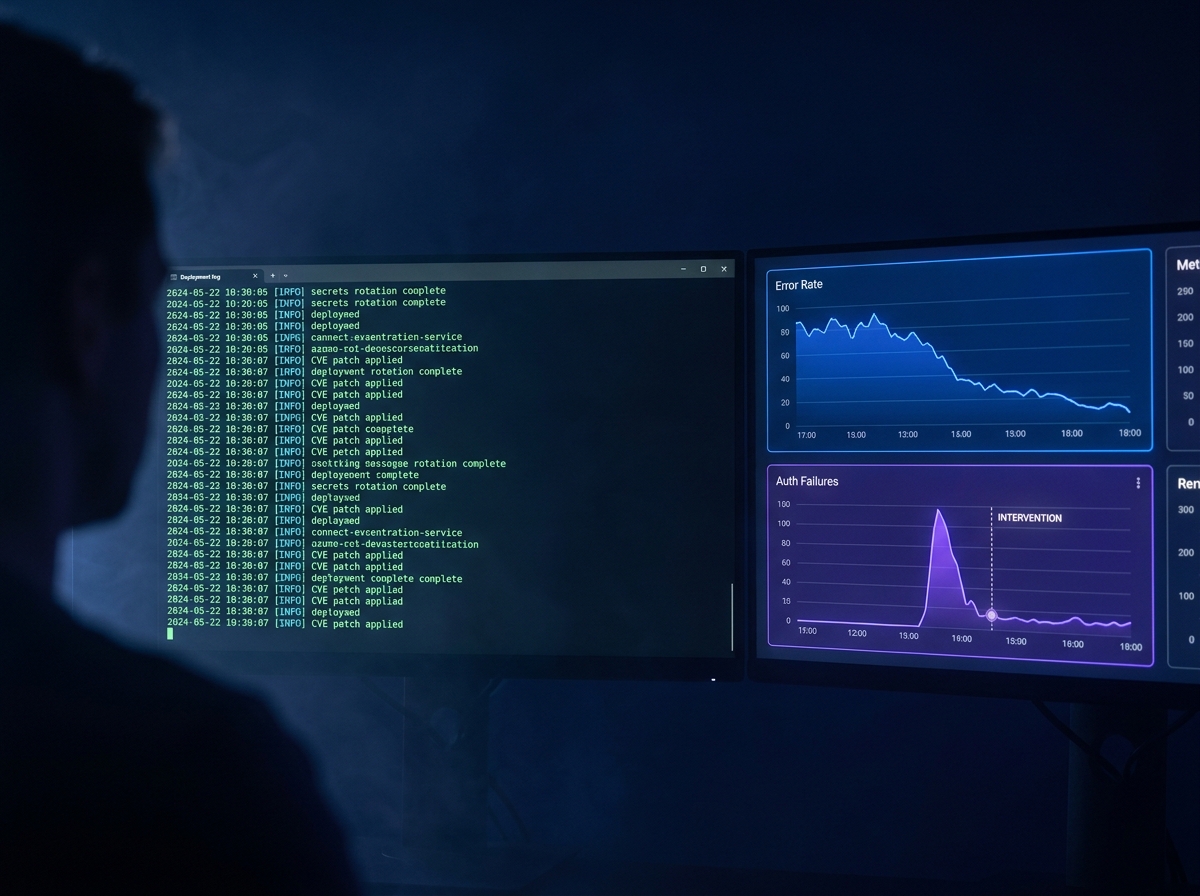
Audit methodology tells you how a vendor thinks. Production track record tells you whether they have lived with the consequences of their own architecture decisions.
The single most reliable signal of a qualified rescue vendor is documented production AI experience: systems they have shipped, operated, and hardened themselves. The single most reliable disqualifier is any vendor who promises a full rescue without a discovery phase or who cannot name the SAST/DAST tools they will use on day one.
The failure pattern here is structural. Common rescue failures include letting the AI agent drive architecture decisions, shipping code the team does not fully understand, and over-reliance on AI-generated output without humans reviewing the result. Vendors who pitch "we'll AI-rescue your AI code" without explicit human-in-the-loop engineering are replicating the original failure mode with better marketing copy.
Picture the diligence call. You ask the vendor to walk you through an AI system they personally run in production. A qualified vendor names the system, the SLA, the median latency, the incident history, and the security patching cadence within sixty seconds. An unqualified vendor pivots to client logos and case studies that stop at the launch announcement.
A concrete benchmark for what production AI experience looks like: our AI Receptionist, Hello, runs on our own production phone line. It hits 1.7-second median response time, with 76% of turns completing under 2 seconds across 512 measured conversation turns, and has had zero downtime since its early 2026 deployment. Before you sign with any rescue vendor, ask them directly: what AI system have you personally shipped, hardened, and monitored for the last twelve months?
The objection that holds partial force: requiring first-party AI products excludes capable agencies that have done strong client work without building their own products. That is fair. Client work counts. But it has to include named systems, specific SLAs, and operational metrics: uptime records, incident response times, security patching cadence. Case studies that stop at launch are evidence of successful delivery to a handoff point, not evidence of production hardening. What happened after the handoff is the part that matters for a rescue engagement.
Prompt-level security practice is another reliable signal. Research found that adding "secure" to code-generation prompts reduces vulnerability density by 28 to 43%, and that persona-based security prefixes reduce vulnerable code output by 47 to 56%. A vendor who cannot speak fluently to prompt-level security controls is working below the current state of practice. Ask them whether they use security-prefixed prompts in their AI-assisted development workflow and what the effect is on their SAST findings. A vendor with real production experience will answer specifically. A vendor without it will reframe the question.
The disqualifiers are concrete. Remove any vendor from your shortlist who cannot name the SAST/DAST tools they will deploy, who declines a paid discovery phase, or whose client references include only visual assets and launch announcements with no operational data attached. These standards reflect the difference between a vendor who has absorbed the cost of their own architecture decisions and one who has not.
The Decision That Actually Matters

Before signing with any vendor on your shortlist, require a paid, two-week architecture and security audit. The deliverable is a written report covering SAST/DAST findings, secrets exposure, data model risks, and a prioritized hardening plan.
If a vendor refuses a paid audit, remove them from consideration. If they cannot produce sample audit deliverables from prior engagements, remove them from consideration. The refusal is the answer. Vendors who have done this work systematically before have the artifact. Vendors who have not will offer alternatives: a "rapid assessment," a "discovery sprint," a "kickoff workshop." None of those produce the written report you will take to your board.
The audit is the first test of whether the vendor can do the work they are selling you. A vendor who produces a rigorous, structured audit report in two weeks has already demonstrated they can operate the way you need them to operate for the full engagement. A vendor who cannot has shown you something equally useful: that you were about to hire your second rescue, not your last one.
Your vibe-coded MVP is already in production, already exposed, and already compounding debt by the week. Knowing how to choose a vibe coding rescue vendor comes down to one test: can they show you, in writing, exactly what is broken and in what order to fix it? The right starting point is the questions to ask before signing with an AI development company. Anything less is a vendor asking you to fund their discovery process on your risk.

About the Author:
Chief Technology Officer | Software Architect | Builder of AI, Products, and Teams
Juan Pablo Lorandi is the CTO at Azumo, with 20+ years of experience in software architecture, product development, and engineering leadership.

.avif)

.avif)
