
The vector database market has exploded from $1.73 billion in 2024 to a projected $10.6 billion by 2032, and there's a good reason for this incredible growth. As businesses rush to build smarter AI applications, Retrieval-Augmented Generation (RAG) has become the secret sauce that makes large language models actually useful for real-world problems. We regularly evaluate RAG tools to help clients select vector databases, embedding models, and orchestration frameworks that align with their production requirements.
Your AI chatbot might be brilliant at writing poetry, but ask it something specific about your company's specific policies or last quarter's sales, and it has no idea. That's where RAG comes in. RAG enhances the accuracy and reliability of generative AI models by fetching facts from external sources. It's like giving your AI a really good research assistant.
But catch this: RAG applications need somewhere to cache and restore quickly all that context data. That's where vector databases shine. While normal databases store data in neat rows and columns, vector databases store data in mathematical vectors. This makes it appallingly quick to find similar or related content.
In this guide, we will take you through the top vector database solutions bringing RAG apps to life, from cloud-native innovators to developer-focused open-source options. Whether you're building your first chatbot or growing an enterprise knowledge system, you'll find the perfect fit for you.
Quick Comparison: Top Vector Database Solutions at a Glance
Database Key Features Primary Use Cases Scalability Pricing Model Deployment Options Pinecone Managed service, sub-millisecond queries, multi-cloud Conversational AI, semantic search Enterprise-ready Usage-based Cloud-native Qdrant Rust performance, hybrid search, flexible deployment Enterprise knowledge bases, customer support High-scale Free/Paid tiers Docker, Kubernetes, Cloud Weaviate Built-in ML models, GraphQL API, multi-modal Multi-modal RAG, content management Medium-scale Free/Paid tiers Cloud/On-premise Chroma Simple API, local development, LangChain integration RAG prototyping, small applications Small-scale Open-source Local/Cloud Milvus Massive scale, distributed architecture, multiple indexes Enterprise search, recommendation systems Massive scale Open-source/Cloud Flexible MongoDB Atlas Unified platform, existing MongoDB integration Hybrid applications, content platforms Enterprise-ready Usage-based Global clusters1. Pinecone: The Cloud-Native RAG Champion
If you want to build RAG applications without worrying about infrastructure headaches, Pinecone is probably your best friend. This fully managed vector database service has become the go-to choice for teams who want to focus on building great AI experiences rather than managing servers and scaling databases.
What makes Pinecone special is its laser focus on making vector search simple and fast. You don't need to be a database expert to get started, and you definitely don't need to worry about performance optimization or scaling issues. It just works, and it works really well.
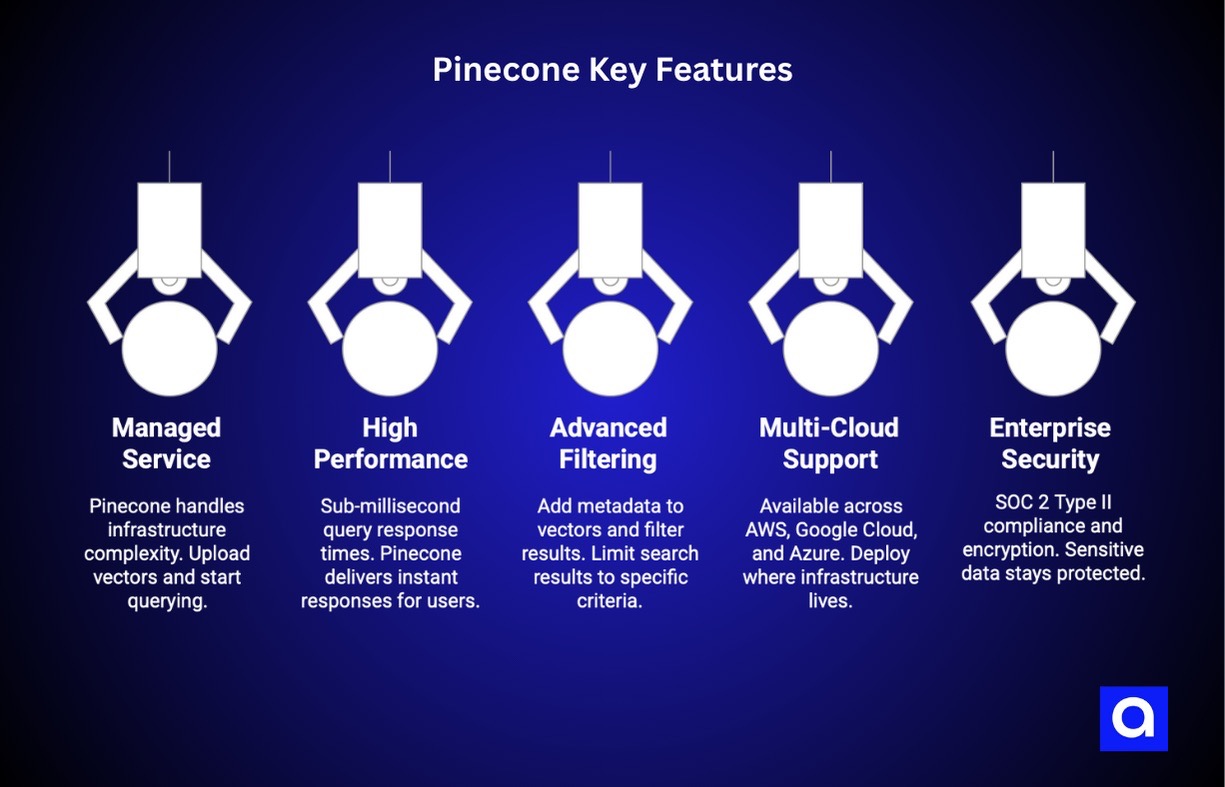
Key Features:
- Managed Service: Pinecone handles all the infrastructure complexity for you. No servers to manage, no scaling decisions to make, no late-night database crashes to fix. You just upload your vectors and start querying.
- High Performance: We're talking sub-millisecond query response times here. When your users are chatting with an AI assistant, they expect instant responses, and Pinecone delivers.
- Advanced Filtering: You can add metadata to your vectors and filter results based on specific criteria. This is huge for RAG applications where you might want to limit search results to specific document types, date ranges, or user permissions.
- Multi-Cloud Support: Available across AWS, Google Cloud, and Azure, so you can deploy wherever your existing infrastructure lives.
- Enterprise Security: SOC 2 Type II compliance and encryption at rest and in transit. Your sensitive data stays protected.
Use Cases:
Pinecone shines in conversational AI applications where you need to give chatbots access to specific knowledge bases. Companies use it to power customer support bots that can instantly find relevant help articles, or internal AI assistants that can answer questions about company policies and procedures.
It's also excellent for semantic search applications. Instead of relying on keyword matching, you can build search systems that understand the meaning behind queries. Users can ask "How do I reset my password?" and get relevant results even if your documentation uses different wording.
Bottom Line: Pinecone is ideal for teams wanting a hassle-free, high-performance solution for production RAG applications without infrastructure management complexity. If you value your time and want to ship fast, this is your database.
2. Qdrant: The Open-Source Performance Leader
Qdrant (pronounced "quadrant") is one of the top vector database solutions that proves open-source doesn't mean compromising on performance. Built in Rust, it's designed from the ground up to be memory-safe and blazingly fast, making it a favorite among cost-conscious organizations that still need enterprise-grade capabilities.
What sets Qdrant apart is its focus on giving you complete control over your vector search infrastructure while delivering performance that rivals any commercial solution. You get the flexibility of open-source with the reliability you need for production applications.
At Azumo, we've worked with Qdrant on a few client projects, and we’ve been impressed with its ability to provide high-performance vector search with flexibility and control. The combination of Rust's performance and Qdrant's ability to integrate hybrid search (both traditional keyword and vector similarity search) has made it a powerful tool for enterprise knowledge bases and customer support systems. The ability to deploy it on Kubernetes or as a managed cloud service is ideal for companies with varied infrastructure needs.
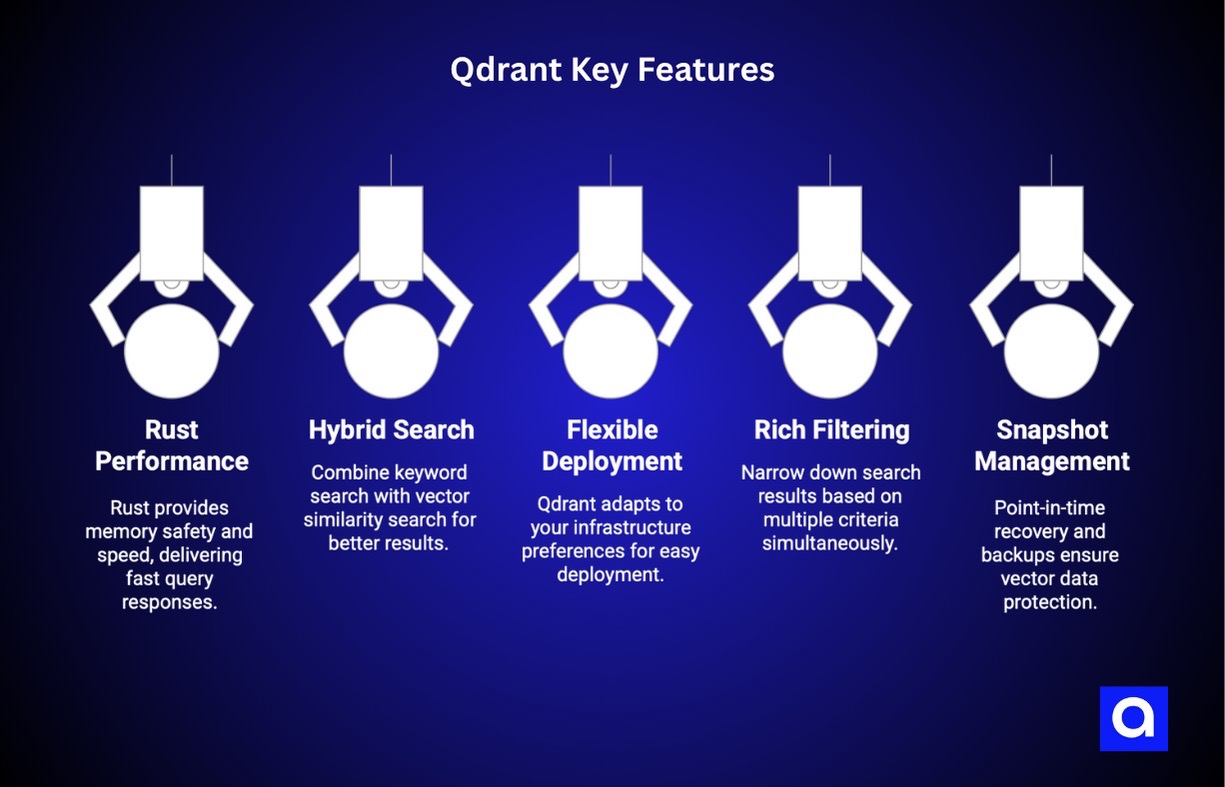
Key Features:
- Rust Performance: Rust isn't just a trendy programming language; it's a performance powerhouse. Qdrant leverages Rust's memory safety and speed to deliver consistently fast query responses, even under heavy load.
- Hybrid Search: This is where Qdrant gets really interesting. You can combine traditional keyword search with vector similarity search in a single query. This means better, more relevant results for your RAG applications.
- Flexible Deployment: Whether you want to run it in Docker containers, deploy on Kubernetes, or use their managed cloud service, Qdrant adapts to your infrastructure preferences.
- Rich Filtering: Complex metadata filtering capabilities let you build sophisticated RAG systems where you can narrow down search results based on multiple criteria simultaneously.
- Snapshot Management: Point-in-time recovery and backups ensure your vector data is always protected, which is critical for production RAG applications.
Use Cases:
Qdrant excels in enterprise knowledge base applications where you need to search through massive amounts of internal documentation, policies, and procedures. The hybrid search capability is particularly valuable here because users might search using both specific terms and conceptual queries.
Customer support teams love Qdrant for building context-aware ticket routing systems. When a support request comes in, the system can automatically find similar past issues and suggest solutions or route the ticket to the right specialist.
Research organizations use Qdrant for academic paper and patent search systems, where the ability to find conceptually similar research across different terminology and languages is invaluable.
Bottom Line: Perfect for organizations seeking open-source flexibility with enterprise-grade performance for large-scale RAG deployments. If you want control over your infrastructure and costs without sacrificing performance, Qdrant delivers.
3. Weaviate: The AI-Native Knowledge Graph
Weaviate takes a different approach to vector databases by building AI capabilities right into the core system. Instead of just storing and retrieving vectors, Weaviate understands your data and can automatically generate embeddings, classify content, and even answer questions about your data using built-in language models.
Think of Weaviate as the Swiss Army knife of vector databases. It's not just a storage system; it's an AI-powered knowledge platform that can understand relationships between different types of data and provide intelligent insights.
We’ve had the opportunity to experiment with Weaviate in smaller-scale AI-driven projects, particularly for use cases that require multi-modal data handling (e.g., combining images and text for product recommendations). The built-in machine learning models are an attractive feature that streamlines the embedding process, which is usually a significant bottleneck in RAG applications. If you need more than just vector storage (if you need AI capabilities right in the database) Weaviate’s built-in classification and automatic embedding generation makes it a unique offering in the vector database space.
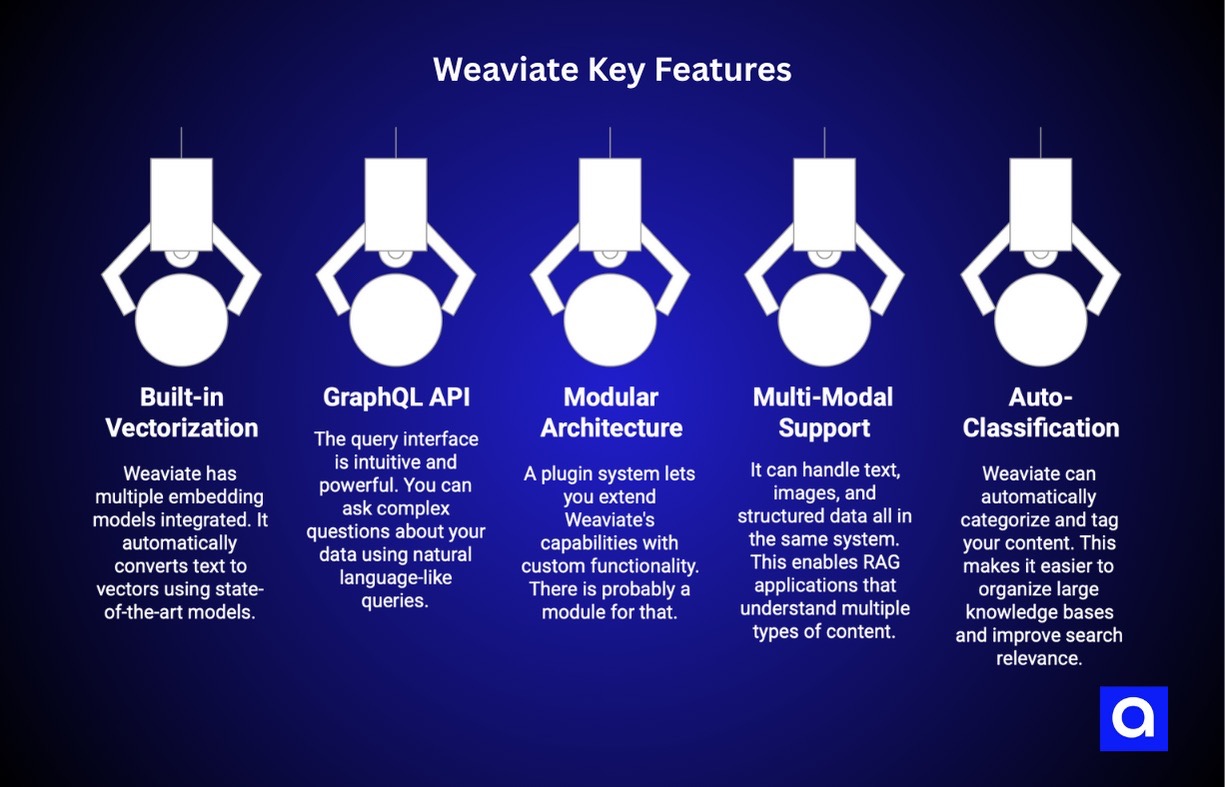
Key Features:
- Built-in Vectorization: Weaviate comes with multiple embedding models already integrated. You can upload text, and it automatically converts it to vectors using state-of-the-art models. No need to manage separate embedding services.
- GraphQL API: The query interface is intuitive and powerful. You can ask complex questions about your data using natural language-like queries, making it easier for developers to build sophisticated RAG applications.
- Modular Architecture: A plugin system lets you extend Weaviate's capabilities with custom functionality. Need a specific embedding model or want to integrate with a particular service? There's probably a module for that.
- Multi-Modal Support: This is where Weaviate really shines. It can handle text, images, and structured data all in the same system, enabling RAG applications that understand multiple types of content.
- Auto-Classification: Weaviate can automatically categorize and tag your content, making it easier to organize large knowledge bases and improve search relevance.
Use Cases:
Multi-modal RAG applications are Weaviate's sweet spot. Imagine a customer service system that can understand both text descriptions and product images, or a research tool that can find relevant information across documents, charts, and diagrams.
Content management systems benefit hugely from Weaviate's auto-classification features. Upload a bunch of documents, and Weaviate automatically organizes them by topic, sentiment, and relevance, making it much easier to build intelligent content discovery systems.
E-commerce companies use Weaviate for natural language product search. Customers can describe what they're looking for in their own words, and the system finds relevant products even if the descriptions don't match exactly.
Bottom Line: Weaviate is one of the top vector database solutions for teams building sophisticated RAG applications requiring multi-modal understanding and integrated AI capabilities. If your RAG system needs to be smart about different types of content, Weaviate is your answer.
4. Chroma: The Developer-Friendly Embedding Store
Chroma is the vector database that gets out of your way and lets you focus on building. Designed specifically for developers who want to experiment with RAG applications quickly, Chroma prioritizes simplicity and ease of use without sacrificing functionality.
If you're just getting started with RAG or building smaller-scale applications, Chroma removes all the complexity that can make vector databases intimidating. You can literally have a working RAG system running in minutes, not hours.
Chroma is considered one of the top vector database solutions for rapid prototyping and smaller-scale RAG projects, and Azumo has used it extensively in internal AI proof-of-concept applications. Its simplicity and developer-friendly API mean we can experiment with different embeddings and test RAG setups quickly without getting bogged down by complex database configurations. Chroma's native support for LangChain makes it particularly useful for teams looking to integrate with existing AI agent frameworks with minimal friction.
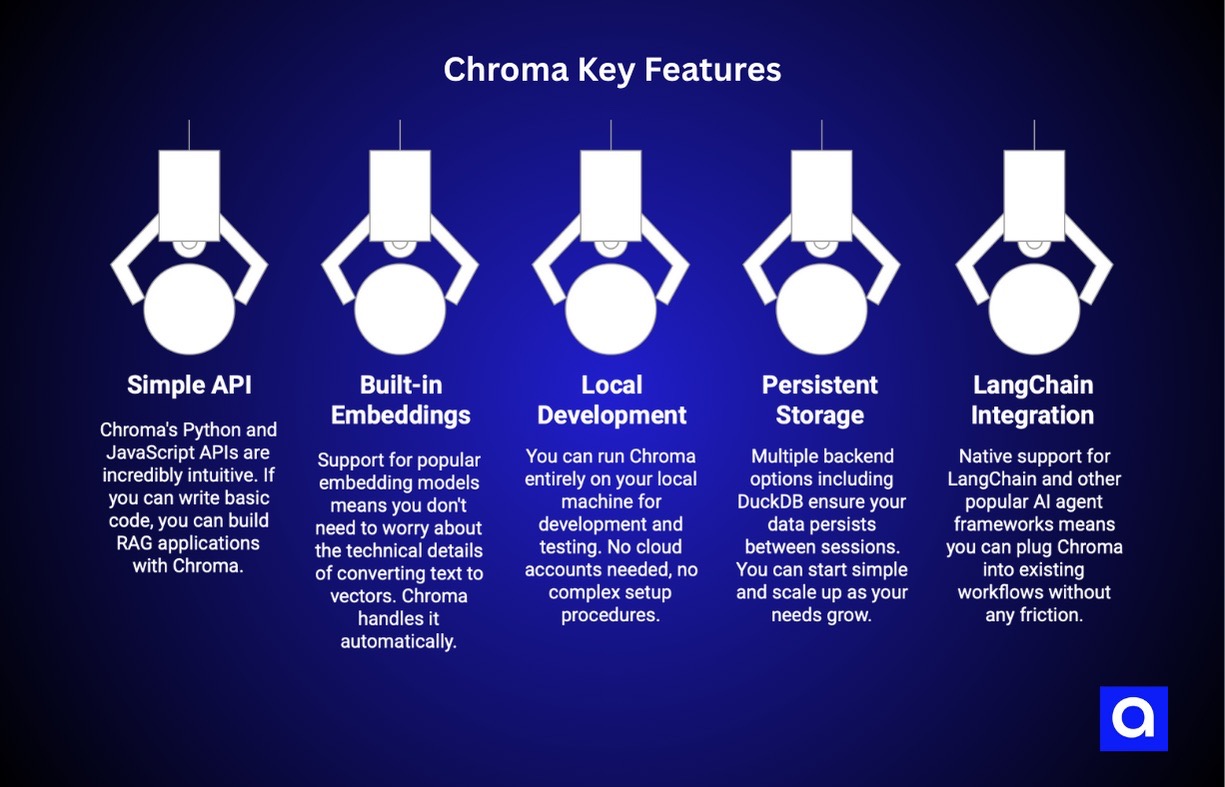
Key Features:
- Simple API: Chroma's Python and JavaScript APIs are incredibly intuitive. If you can write basic code, you can build RAG applications with Chroma. The learning curve is practically flat.
- Built-in Embeddings: Support for popular embedding models means you don't need to worry about the technical details of converting text to vectors. Chroma handles it automatically.
- Local Development: You can run Chroma entirely on your local machine for development and testing. No cloud accounts needed, no complex setup procedures. Just install and go.
- Persistent Storage: Multiple backend options including DuckDB ensure your data persists between sessions. You can start simple and scale up as your needs grow.
- LangChain Integration: Native support for LangChain and other popular AI agent frameworks means you can plug Chroma into existing workflows without any friction.
Use Cases:
RAG prototyping is where Chroma absolutely excels. Data scientists and developers use it to quickly test ideas, experiment with different embedding models, and validate RAG concepts before committing to more complex infrastructure.
Small-scale applications and startups love Chroma because it lets them build sophisticated AI features without the overhead of managing complex database systems. You can launch a smart chatbot or semantic search feature in days, not weeks.
Educational projects and research environments benefit from Chroma's simplicity. Students learning about RAG and vector databases can focus on understanding the concepts rather than wrestling with configuration files and deployment procedures.
Bottom Line: Ideal for developers and small teams starting their RAG journey who prioritize simplicity and rapid prototyping over enterprise features. If you want to build and iterate fast, Chroma gets you there.
5. Milvus (Zilliz Cloud): The Scalable Enterprise Solution
When you need to handle billions of vectors and serve thousands of concurrent users, Milvus is the vector database that won't break a sweat. Originally developed by Zilliz, Milvus is built for massive scale from the ground up, with a distributed architecture that can grow with your business.
What makes Milvus special is its ability to handle enterprise-scale workloads while remaining flexible enough to deploy anywhere. Whether you want to run it on-premises, in the cloud, or in a hybrid setup, Milvus adapts to your infrastructure requirements.
We’ve worked with Milvus for large-scale enterprise search applications, and we’ve been impressed with its distributed architecture, which allows it to handle billions of vectors seamlessly. Whether it's a recommendation engine, fraud detection, or enterprise-wide search, Milvus has proven its ability to scale without compromising on speed or accuracy. Its flexibility in deployment (on-premise or cloud) and support for multiple indexing algorithms make it a reliable choice for enterprise clients that need the robustness of an industrial-grade vector database.
Key Features:
- Massive Scale: Milvus can efficiently handle billions of vectors across distributed clusters. As your RAG application grows from thousands to millions of users, Milvus scales seamlessly.
- Multiple Indexes: Various indexing algorithms optimize for different use cases. Whether you prioritize query speed, memory usage, or accuracy, there's an index type that fits your needs.
- Distributed Architecture: Horizontal scaling capabilities mean you can add more nodes to handle increased load. No single points of failure, no performance bottlenecks.
- Cloud and On-Premise: Complete flexibility in deployment options. Use Zilliz Cloud for managed hosting, or deploy Milvus on your own infrastructure for maximum control.
- Rich SDKs: Support for Python, Java, Go, Node.js, and other languages makes it easy to integrate Milvus into existing applications regardless of your tech stack.
Use Cases:
Enterprise search applications are Milvus's bread and butter. Large organizations use it to build company-wide knowledge systems that can search through millions of documents, emails, and other content in real-time.
Recommendation systems at scale rely on Milvus to power personalization engines that serve millions of users simultaneously. E-commerce giants and streaming platforms use it to deliver relevant suggestions in milliseconds.
Fraud detection systems leverage Milvus for real-time similarity analysis, comparing new transactions against patterns from billions of historical records to identify suspicious activity instantly.
Bottom Line: Milvus is one of the top vector database solutions for enterprises requiring massive scale RAG applications with the flexibility to deploy anywhere. If you're building for millions of users and billions of data points, Milvus handles it all.
6. MongoDB Atlas Vector Search: The Integrated Database Solution
MongoDB Atlas Vector Search brings vector capabilities into the database you probably already have a love affair with. Instead of building a second database for your stack, you can build RAG apps on top of your existing MongoDB infrastructure, using legacy document storage and modern vector search within one platform.
This approach is particularly appealing for teams that want to add AI capabilities to existing applications without the complexity of managing multiple database systems. Your user data, application data, and vector embeddings can all live in the same place.
We’ve seen MongoDB Atlas become a favored choice for clients who are already using MongoDB for their data needs. The addition of vector search capability to the existing MongoDB platform is a game-changer for businesses wanting to add RAG capability without needing to overhaul their overall data architecture. The addition allows for the joint management of structured and unstructured data, which can be essential for hybrid applications that require a combination of traditional database capabilities and AI-driven capabilities.
Key Features:
- Unified Platform: Store documents, user data, and vector embeddings in the same database. This simplifies your architecture and reduces the complexity of keeping different data stores in sync.
- Atlas Integration: Leverages MongoDB's existing global infrastructure, security features, and operational tools. If you're already comfortable with MongoDB operations, vector search feels familiar.
- Flexible Schema: Handle both structured business data and unstructured vector data together. This is perfect for applications that need to combine traditional database operations with AI-powered search.
- Global Clusters: Multi-region deployment capabilities ensure your RAG applications perform well for users anywhere in the world.
- Enterprise Security: Advanced security features and compliance certifications that enterprises require, all built into the platform you already trust.
Use Cases:
Hybrid applications that combine traditional database operations with AI-powered search are MongoDB's sweet spot. Think customer relationship management systems that can find similar customers based on behavior patterns, or content management platforms that can suggest related articles.
Content platforms benefit from having user profiles, content metadata, and semantic search capabilities all in one system. You can personalize content recommendations based on both explicit user preferences and semantic similarity of content.
Analytics integration becomes much simpler when your transactional data and vector search capabilities live in the same database. Business intelligence tools can combine traditional reporting with AI-powered insights without complex data pipeline management.
Bottom Line: Perfect for organizations already using MongoDB who want to add RAG capabilities without introducing new database infrastructure. If you want to keep your stack simple while adding AI superpowers, this is your solution.
Key Considerations for Selecting Vector Database Solutions for RAG
Choosing the right vector database can make or break your RAG application's performance, scalability, and cost-effectiveness. Here's what you need to think about when evaluating your options:
Query Performance
Your RAG application is only as good as its response time. Users expect instant answers, so look for databases that can deliver sub-second query responses even under heavy load. Consider both average response times and tail latencies (the slowest 5% of queries) because those outliers can ruin user experience.
Scalability Requirements
Think beyond your current needs. How much data will you have in six months? A year? Some databases excel at small to medium workloads but struggle at enterprise scale, while others are overkill for simple applications. Match your database choice to your growth trajectory.
Integration Capabilities
Your vector database doesn't exist in isolation. How well does it play with your existing AI/ML stack? Look for native integrations with popular frameworks like LangChain, Haystack, or LlamaIndex. The easier the integration, the faster you'll ship.
Deployment Preferences
Do you need cloud-native simplicity, on-premises control, or hybrid flexibility? Some databases lock you into specific deployment models, while others give you options. Consider your security requirements, compliance needs, and operational preferences.
Cost Structure
Vector databases have different pricing models, from usage-based cloud services to open-source solutions with operational costs. Factor in not just the database costs, but also the engineering time needed for setup, maintenance, and scaling.
Developer Experience
Developer experience often becomes the unsung differentiator, where comprehensive documentation, active communities, and intuitive APIs can save hundreds of engineering hours. Advanced capabilities like hybrid search, multi-tenancy support, and granular access controls may prove essential depending on your use case.
The Future of AI Relies on Vector Databases—and the Right Partner
The vector database market’s explosive growth isn’t just a trend—it’s the backbone of the next generation of AI applications. From powering hyper-accurate RAG systems to enabling real-time anomaly detection, these databases are the unsung heroes making AI truly useful.
But building with vector databases isn’t just about choosing the right technology. It’s about having a partner who understands how to optimize, scale, and integrate them into your unique workflows.
At Azumo, our vector database development services have helped companies like Meta harness vector databases to solve real-world problems: whether it’s supercharging enterprise search, detecting fraud, or delivering personalized recommendations. With a 4.9 Clutch rating and a 94% client retention rate, we don’t just build solutions; we ensure they deliver lasting impact.
Ready to unlock the full potential of vector databases for your AI projects?
Get in touch with our experts today!

About the Author:
Chief Technology Officer | Software Architect | Builder of AI, Products, and Teams
Juan Pablo Lorandi is the CTO at Azumo, with 20+ years of experience in software architecture, product development, and engineering leadership.

.avif)

.avif)
